
With the upcoming Open edX release, Maple, the edX team is pleased to share a piece of technology they’ve been using internally for awhile. This tool is called CourseGraph, and is now available as an unsupported part of devstack and Maple. CourseGraph allows you to answer questions you may have about the content of all your instance’s courses in aggregate, such as counts & locations of specific XBlocks, questions pertaining to the structure of your courses, questions about exams, and more!
At edX, usage of CourseGraph is restricted to the Customer Support and Engineering teams. These teams find it useful to be able to answer questions answered by aggregate statistics; their Partner Support team particularly is often able to help debug instructor issues in Studio with an XBlock query. The Engineering team gets insights into all kinds of potential issues – such as figuring out where “orphan blocks” (blocks that are not reachable from the course root via children) are.
What is CourseGraph?
CourseGraph is a graphical representation of your instance’s course content in neo4j, a popular graph database; CourseGraph is not a runtime API. The advantage of representing course data in graph form is that it allows you to write broad queries about both course content and structure. Using CourseGraph assumes you have a basic familiarity with the course data model, that courses are graphs, usually trees, where each node is an XBlock.
So What?
Have you ever had questions like:
- Course teams (and others!) might wonder…
- Where are all the video components in my course? What are all their titles and IDs?
- What ORA (open response assessment) units have misconfigured dates? (misconfigured dates may block learners from accessing the assignment)
- What are the types of blocks (such as problem or ORA) I use in my course, and how frequently do I use those blocks?
- Developers/site operators/support teams might wonder…
- How many currently-running courses are using a specific type of block?
- Where are all of an org’s videos and what video source / URL are they being served from?
- Which courses use LTI components, and which ones of those are graded?
Right now, it’s really difficult to answer these questions, given the way course data is stored in Mongo. Split Mongo, which is the backend of nearly all your running courses, is optimized for loading an individual course at a time, not for broad queries across multiple course structures. Reconstructing each course’s graph-like structure would require a good deal of processing outside of a pure Mongo query. The other advantage of using neo4j is that it comes with a query result visualizer built in, so you can see the graph structures of parts of courses.
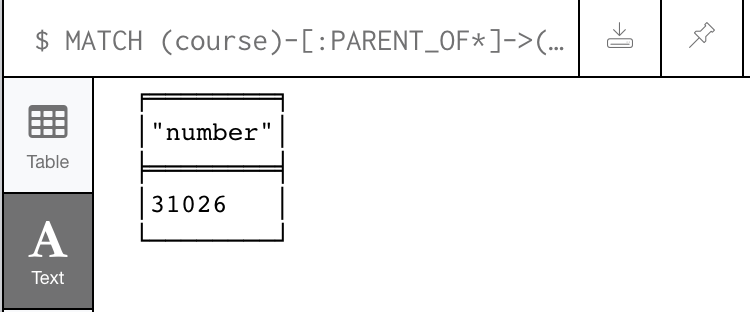
The following query counts the number of jsinput problems across your Open edX instance:
MATCH
(course)-[:PARENT_OF*]->(p:problem)
WHERE
p.data
CONTAINS
‘jsinput’
RETURN
count(p) as number
and returns the following result (31026):
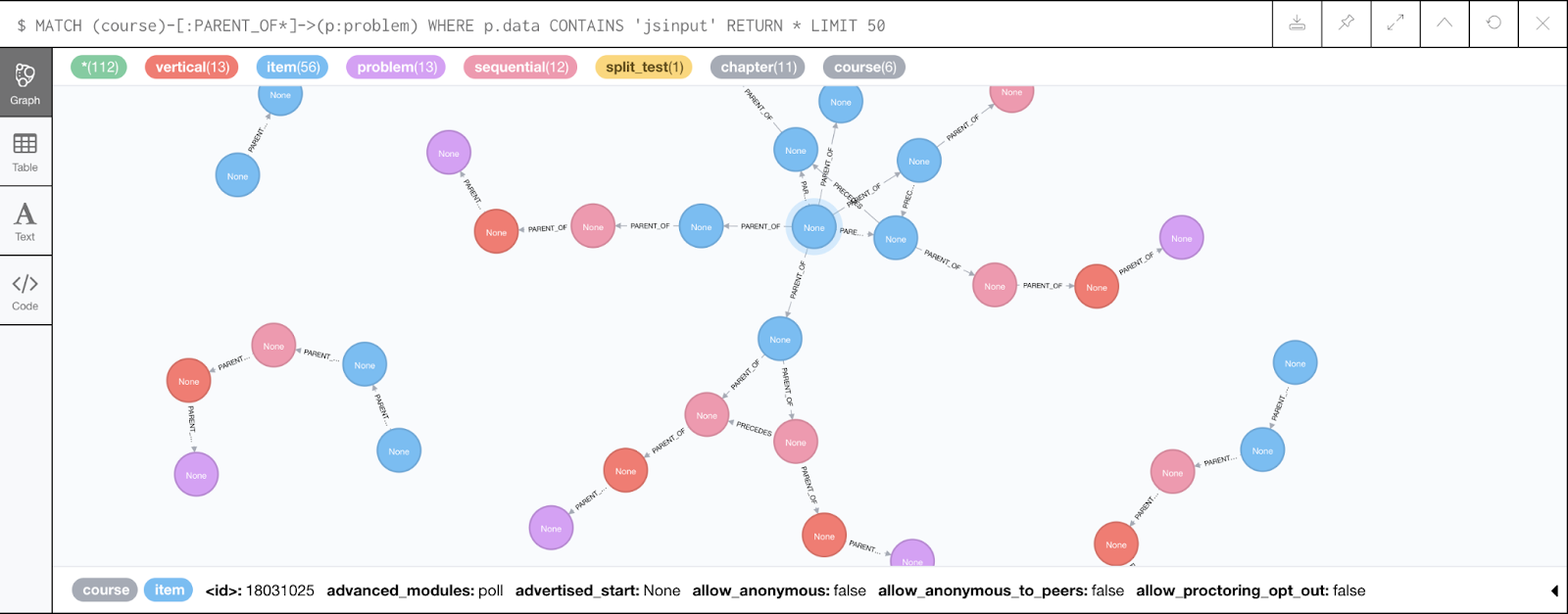
You can also see the data visually, when the result of the query are nodes. This query is identical to the previous one except we RETURN * and limit the result to 50 items. The nodes and their PARENT OF relationships are shown in the graph. Hovering over a node displays, in the bottom bar, the attributes set on that node.
What’s the data structure?
Neo4j is a graph database, and so, like a graph, has two fundamental datatypes: nodes and edges. In CourseGraph’s case, nodes are XBlocks: course blocks, problems, verticals, htmls, etc. Attributes on that node correspond to the fields on the XBlock. In addition, each node has course_key, org, course, run, edited_on, and location attributes set on them as well.
Edges represent how the nodes are related. There are two types of relationships between blocks: “PARENT_OF”, which links a block to its child, and “PRECEDES”, which links a block to its sibling. So a vertical may be a PARENT_OF a video block; in a sequence of two verticals, the first vertical will “PRECEDES” the second one.
How do I write queries against it?
Neo4j uses its own query language, cypher. It’s similar to SQL, so it won’t take too long to get the hang of. Check out this handy refcard for useful tips! At edX, we’ve continuously taken note of useful queries; see what we’ve come up with – and add your own! – on the CourseGraph query collection page.
Here’s a more complicated query, that goes through a course on your instance (here, the edx.org “DemoX” course), and outputs all learner-visible XBlocks of type “problem” in the course, annotated with its display name, the name of the vertical that contains it, and when it was last edited:
MATCH
(c:course) -[:PARENT_OF*]-> (v:vertical) -[:PARENT_OF*]-> (n:item)
WHERE
c.course_key = ‘course-v1:edX+DemoX.1+2T2019’
AND
n.block_type = ‘problem’
AND
n.visible_to_staff_only = false
RETURN
n.block_type,
n.display_name,
v.display_name as unit_location,
n.edited_on
ORDER BY
n.edited_on;
Here’s the first 16 results, of 17 as mentioned in the final line:

How do I deploy and operate CourseGraph?
The Nutmeg release (anticipated for June 2022) will include a CourseGraph plugin for Tutor! Check out the plugin’s README to learn how Nutmeg operators will be able to easily install, configure, and run CourseGraph as part of their Tutor-managed Open edX deployment. (For Open edX instances running a release older than Nutmeg, there is no offically-recommended method for deploying CourseGraph.)
As of Nutmeg, the plugin is in “Beta” status, and its maintainers are actively looking for users who are willing to try it in a production setting and provide feedback. To ask questions, report bugs, or share your experiences with CourseGraph, please open a GitHub Issue on the tutor-contrib-coursegraph repository.
We hope this tool is helpful to you!
![]()